Gemini 2.0 Flash: A Paradigm Shift in RAG Models

Google’s release of Gemini 2.0 Flash1 has sent ripples through the AI community, prompting a re-evaluation of established techniques, particularly Retrieval-Augmented Generation (RAG). This article delves into the implications of Gemini 2.0 Flash and explores how it is changing the landscape of RAG models.
Understanding RAG: The Old Way
RAG models were initially developed to address the limitations of AI models with limited context windows. Retrieval-Augmented Generation (RAG) is a framework that enhances the capabilities of large language models (LLMs) by enabling them to access and incorporate information from external sources during the generation process.
The traditional RAG process involves:
- Chunking: Breaking down large documents into smaller, manageable chunks.
- Embedding: Converting these chunks into vector embeddings and storing them in a vector database.
- Retrieval: When a query is posed, the system retrieves the most relevant chunks from the vector database.
- Augmentation: The retrieved chunks are combined with the original query and fed into the LLM.
- Generation: The LLM generates a response based on the augmented input.
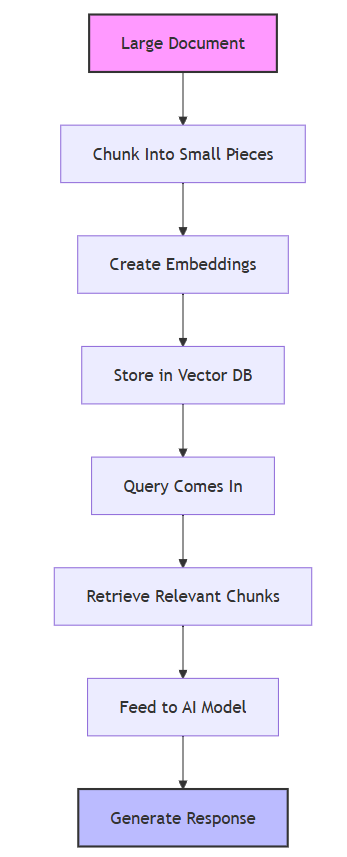 Traditional RAG implementations
Traditional RAG implementations
This approach allowed models to access information beyond their original training data, improving accuracy and relevance. RAG has become popular, as seen with Perplexity and Bing’s AI search. Also, uploading files to ChatGPT also uses RAG. However, this process was complex, requiring significant overhead in terms of data preparation and retrieval mechanisms.
Gemini 2.0 Flash: A Game Changer
Gemini 2.0 Flash boasts a significantly expanded context window, capable of processing up to 1 million tokens, and some models are hitting 2 million. This expanded capacity negates the need for the intricate chunking and retrieval processes that defined traditional RAG.
Key advantages of Gemini 2.0 Flash:
- Elimination of Chunking: The ability to process entire documents at once eliminates the need to break them down into smaller chunks, simplifying the data preparation process.
- Improved Accuracy: Gemini 2.0 Flash exhibits lower hallucination rates, leading to more accurate and reliable results.
- Holistic Reasoning: By processing entire documents, the model can reason across the entire context, providing more comprehensive and nuanced answers.
Implications for RAG
The arrival of Gemini 2.0 Flash does not render RAG entirely obsolete, but it fundamentally alters the approach:
- For Single Documents: Traditional chunking-based RAG is no longer necessary for individual documents that fit within the model’s context window.
- For Large Datasets: When dealing with massive datasets consisting of numerous documents, a modified RAG approach is still valuable:
- Document Retrieval: First, identify relevant documents using search techniques.
- Parallel Processing: Feed the full documents into the AI model separately and in parallel.
- Response Merging: Merge the individual responses to formulate a final answer.
 Gemini 2.0 Direct Document Processing
Gemini 2.0 Direct Document Processing
Practical Example
Consider an earnings call transcript of 50,000 tokens. With traditional RAG, this would need to be divided into smaller chunks. Gemini 2.0 Flash can ingest the entire transcript, providing a more comprehensive understanding of the content. Asking “How does this company’s revenue compare to last year?” will yield a better answer than traditional RAG as the whole transcript is used to formulate the answer.
Conclusion
Gemini 2.0 Flash represents a significant leap forward in AI capabilities. While RAG remains relevant for managing large datasets, the way it is implemented has evolved. The focus has shifted from intricate chunking to efficient document retrieval and leveraging the extensive context windows of modern AI models. As AI technology continues to advance, simplicity and efficiency will be key to unlocking its full potential.
-
https://blog.google/technology/google-deepmind/gemini-model-updates-february-2025/ ↩