The Factorio Learning Environment: A Different Benchmark for Evaluating LLMs and General AI

The quest to evaluate large language models (LLMs) and measure progress toward general artificial intelligence (AGI) has led to creative new benchmarks. One standout example is the Factorio Learning Environment (FLE) – a tool that uses the famously complex factory-building game Factorio to test AI systems’ reasoning, planning, and problem-solving abilities. This article explores how FLE works, its implications for AGI development, and what it reveals about modern LLM capabilities.
Why Factorio? A Crucible for Complexity
Factorio tasks players with building automated factories on an alien planet, requiring iterative optimisation of resource chains, spatial layouts, and logistics. Its appeal lies in exponential complexity: early-game tasks involve basic automation, while late-game factories process millions of resources per second. The FLE translates this into a benchmark with two key evaluation modes:
- Lab Play:
- 24 structured tasks requiring agents to build specific production lines (e.g., iron plates, utility science packs).
- Tests incremental problem-solving, with challenges escalating from coordinating 2 machines to managing 100+.
- Open Play:
- Agents aim to build the largest possible factory, measured by resource throughput (30/min to millions/sec).
- Evaluates long-term planning, scalability, and adaptability.
Unlike traditional benchmarks, FLE requires Python code synthesis via a REPL interface. Agents interact programmatically with the game state, mimicking how an AI might interface with real-world systems.
How FLE Evaluates LLMs: Key Insights
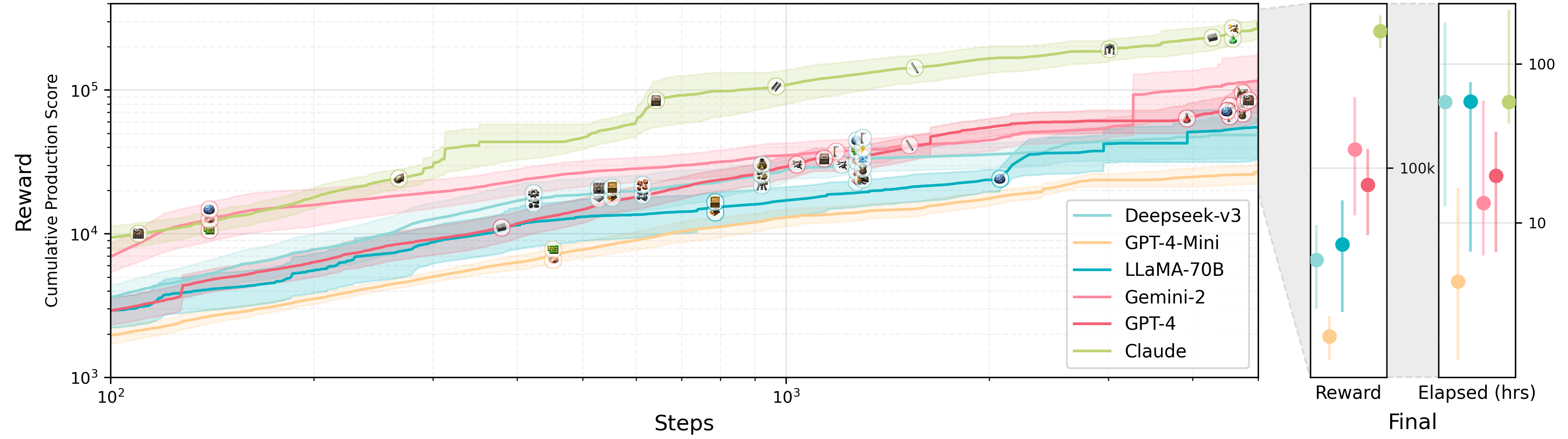
Recent results (leaderboard) highlight critical gaps in LLM capabilities:
- Claude-3.5-Sonnet, the top performer, completes only 7/24 lab tasks, struggling with spatial planning in complex objectives.
- Models excel at small-scale challenges but falter when coordinating multi-step workflows (e.g., combining mining, smelting, and assembly lines).
- Common failure modes (paper):
- Poor spatial reasoning (e.g., inefficient pipe/machine placement).
- Inability to debug systemic issues (e.g., focusing on individual machines rather than topology).
- Limited iterative improvement (agents rarely refine designs after initial implementation).
Rethinking AI Evaluation: Beyond Text Comprehension
FLE exemplifies a shift toward embodied, systems-oriented benchmarks that better approximate real-world AGI challenges. Traditional LLM evaluations (e.g., question answering, code completion) fail to assess:
| Capability | FLE Test |
|---|---|
| Multi-agent planning | Coordinating mining, logistics, production |
| Error correction | Diagnosing throughput bottlenecks |
| Resource scaling | Transitioning from manual to automated systems |
As noted in the FLE paper:
“Success requires agents to combine spatial reasoning, hierarchical planning, and an understanding of exponential scaling – mirroring the challenges of bootstrapping real-world technological systems.”
The Road to General AI: A Hierarchy of Intelligence
FLE’s creators position it as a proxy for measuring “tech tree ascent” – a key component of hypothetical AGI. This aligns with a tiered view of AI capabilities:
- Narrow AI: Excels at specific tasks (e.g., GPT-4 for text generation).
- Broad AI: Adapts to multiple domains (e.g., systems mastering FLE’s lab tasks).
- General AI (AGI): Exhibits human-like flexibility, solving novel problems in open play.
Current LLMs operate between narrow and broad AI. FLE highlights their limitations in systemic innovation – a prerequisite for AGI.
Conclusion: Benchmarking the Path to AGI
The Factorio Learning Environment offers a compelling framework for evaluating AI systems’ ability to manage complexity, mirroring the incremental bootstrapping required for AGI. While no model has yet “beaten” Factorio, FLE provides actionable insights:
- LLMs need better spatial-temporal reasoning modules.
- Future systems must prioritise iterative self-improvement over static solutions.
- Open-ended environments like FLE will be critical for measuring progress toward AGI.
Explore the environment: GitHub Repository